I Built a Document Addressing Standard Because Folders Quit on Me
Last year I was building an ETL pipeline and hit a wall I did not expect. Not the extraction, not the transforms. The naming. Every document coming off the transformation end needed a place to live and a name that said where it lived, and both a human and a machine were going to be reading those names constantly. I could not find a convention that served both without one of them losing.
Today I am releasing what I built to fix that. It is called DAS, the Document Addressing Standard, and it is open source under MIT. Repo, spec, and CLI are at github.com/Hexaxia-Labs/hexaxia-das. This is the story of why it exists and what it is actually for, which is not the thing I thought it was for when I started.
Why do folders and Johnny Decimal fail at scale?
The default answer to “where does this document go” is folders and good file names. That works right up until it does not. One person with consistent instincts and a few hundred files is fine. Add a second author, a few thousand documents, and a couple of years of drift, and the structure turns into noise. There is no map. Nothing tells you which half of the tree you can ignore. I have watched this happen to my own corpora, and “I will remember where I put it” is a promise that expires.
So I went looking, and the closest thing to right was Johnny Decimal. If you have not seen it, JD gives everything a permanent number, two levels deep, with a readable label attached. The core idea is correct and I want to be clear that DAS owes it the lineage: numbers that never change beat folders you keep reorganizing.
But JD was built for one person, and it caps at ten areas of ten categories on purpose. A company with a dozen clients, several service lines, internal departments, and years of history does not fit in a hundred buckets. JD also has nothing a machine can read to understand the address space, and nothing that stops two people from drifting into two different conventions. It is a discipline, not a system. At my scale the discipline rots.
The question that produced it
I kept circling two questions. Can the address be human navigable and readable? Can it be machine navigable and readable? Both came back yes, and once both were yes, DAS was born.
The trick is to stop making the name do one job. DAS gives every document two identities fused into one. A permanent decimal address, 02.01.03, that a machine reads by stripping everything after the first hyphen and a human reads as a coordinate. And a label, Active-Projects, that a person reads and that is free to change when the content changes. They ride together on disk as 02.01.03-Active-Projects/. It is the DNS split applied to files: the address is the IP, the label is the hostname. The hostname can be wrong. The IP does not move.
That separation is the whole game. Labels drift, projects get renamed, folders get reorganized, and none of it breaks anything, because every citation and every pointer runs on the address, not the path. There is a manifest, a single machine-readable map of the whole address space an agent loads once instead of crawling the tree. There is a validator that runs in CI and turns address drift into a failing build instead of a slow rot. The pieces are in the spec, and I would rather you read it there than have me list fields at you.
What is a Document Addressing Standard actually for?
Here is where I was wrong at the start. I thought I was building a faster way to find things. I was not.
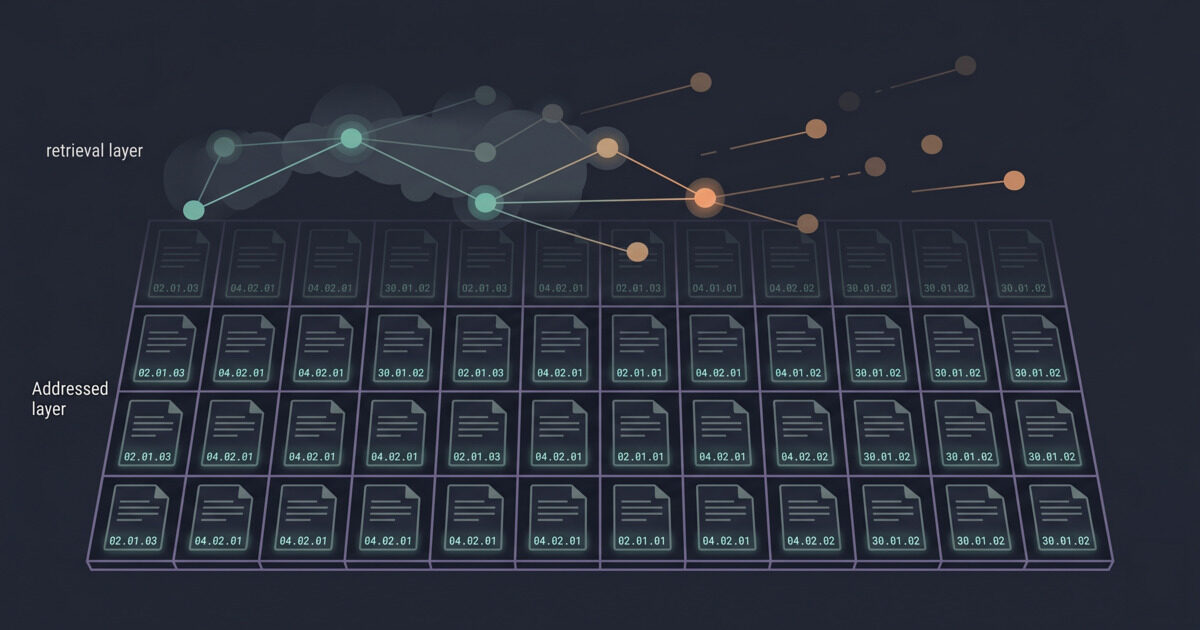
When I benchmarked it, plain RAG over good summaries was the fastest way to navigate. Embeddings won the speed test. If retrieval speed were the whole point, you would not need addresses at all. And that is exactly when I understood what the addresses were really buying me.
A retrieval layer finds things beautifully, right up until it is not there. The service is down. The corpus is air-gapped. A contractor needs to read the documents without your vector store. An auditor wants to see everything in the compliance area and a model embedding it last week does nothing for them. At that moment an embedding-only corpus is a pile of opaque files, and a UUID-named one is worse, because a UUID means nothing without the database that explains it. A DAS address still means something sitting on a bare filesystem. ls still tells you where you are. find still pulls the compliance area with one command.
That is the thing DAS actually is. Not a faster index. A floor. The smart layer on top is an accelerator you have to be able to lose, and the floor is what keeps the corpus usable once you lose it. Cheaper long context and better retrieval models will keep winning the speed race. They do not touch the floor.
And at the scale I run, the floor is not a fallback, it is the default. My agents navigate these corpora with no retrieval layer at all, by address and by manifest, and they do it fine. RAG is an accelerator I reach for when I want it, not a dependency I am stuck with. There is a ceiling on ragless navigation somewhere above my scale, and finding it is part of the open experiment. But the idea that you need a retrieval layer to use a corpus at all is just not true at the size most teams actually work.
Can a Document Addressing Standard store agent memory?
Once I had the floor, it started fitting things that were not documents.
Agent memory is the clearest one, and it is not a thought experiment for me. The memory my agents run on today is a DAS corpus: close to four hundred addressed documents, split into areas for governance, identity, semantic knowledge, episodes, procedures, and entities, with an inbox where raw memory lands and an archive where retired memory goes. I wanted a place for agents to offload the memory that does not need to ride in the context window: the things one agent learns that another could reuse, the durable record that does not belong in the hot path. That is cool storage, and a DAS corpus is a clean fit for it. A permanent address is stable provenance, so “the agent learned this, filed at 30.01.02” is a citation another agent or a post-incident review can trust a year later. You can diff the memory of two agents by diffing two directories. You cannot do that with a vector store.
It worked, and then it ran into the obvious problem: agents do not like eating cool or cold food. Memory on disk is durable and useless until it is in front of the model. So I gave it a microwave. Before a run, the agent deterministically works out how much of which memory it needs, takes it to the microwave, and warms it up. That warmed slice is a pre-buffer. It stays out of the context window until it is needed, and it cuts the tool calls way down when it is. The cool tier is the floor. The microwave is the accelerator on top, and it only works because the floor underneath it is addressed, durable, and the same whether the warm layer is running or not.
That was the moment it stopped being a filing trick for my ETL output and started looking like a pattern. Anything that has to outlive the layer reading it wants a floor like this. The retrieval layer that reads DAS corpora, Rhizome, is also going open source, and the fuller story of how ingestion, addressing, and retrieval fit as a stack is the next post in this series.
It is a position paper, not a victory lap
First, what is real, because I am not floating a proposal. I run more than a dozen corpora on this today. Several hundred addressed documents: client files, my own company’s records, and the agent memory corpus above. This has been the addressing layer under my actual work, not a weekend demo.
What it is not is proven at organizational scale, and I want to be straight about the difference. All of that addressing is my own hand. Deep use by one author shows people can live in a DAS corpus. It does not show the convention survives ten authors and ten thousand documents, and that experiment is still open. The validator enforces the addressing and nothing above it yet. The passport format is markdown-first, the lifecycle commands are not built, and the single-file manifest has a ceiling I already know I will have to break. The paper names every one of those gaps instead of hiding them, because I would rather you adopt this with clear eyes than be sold on it.
If you manage a corpus that has gotten away from you, the fastest way to feel the idea is to try das validate against it. If addressing it is hard, that is the diagnosis: a corpus you cannot address was never going to survive its retrieval layer going down either.
The standard, the CLI, and the full position paper are at github.com/Hexaxia-Labs/hexaxia-das. You can read the paper straight through as a PDF. It carries the argument, the benchmark, and the design rationale in the depth a post should not. Go take it apart.
Part one of the Corpus Lifecycle series. Next: ingestion, addressing, and retrieval as a connected stack, and what it takes to design a corpus where each layer can fail on its own without bringing down the others.
Aaron Lamb Co-Founder, Hexaxia Technologies